
ICLR 2024
Well, hello Vienna! The 12th International Conference on Learning Representations (ICLR) was held at the massive Messe Wien Exhibition Congress Center in the heart of Vienna, Austria just last week and I had the pleasure to attend in person.

It was so inspiring to be surrounded by over 6k in-person attendees (over 7k in total, including virtual attendees), presenting over 2200 machine learning papers in massive poster sessions that had over 300 works each. Over the course of 5 intense days, I had the opportunity to discuss several impressive works with their authors, attend fantastic keynotes, and network with titans from around the world.
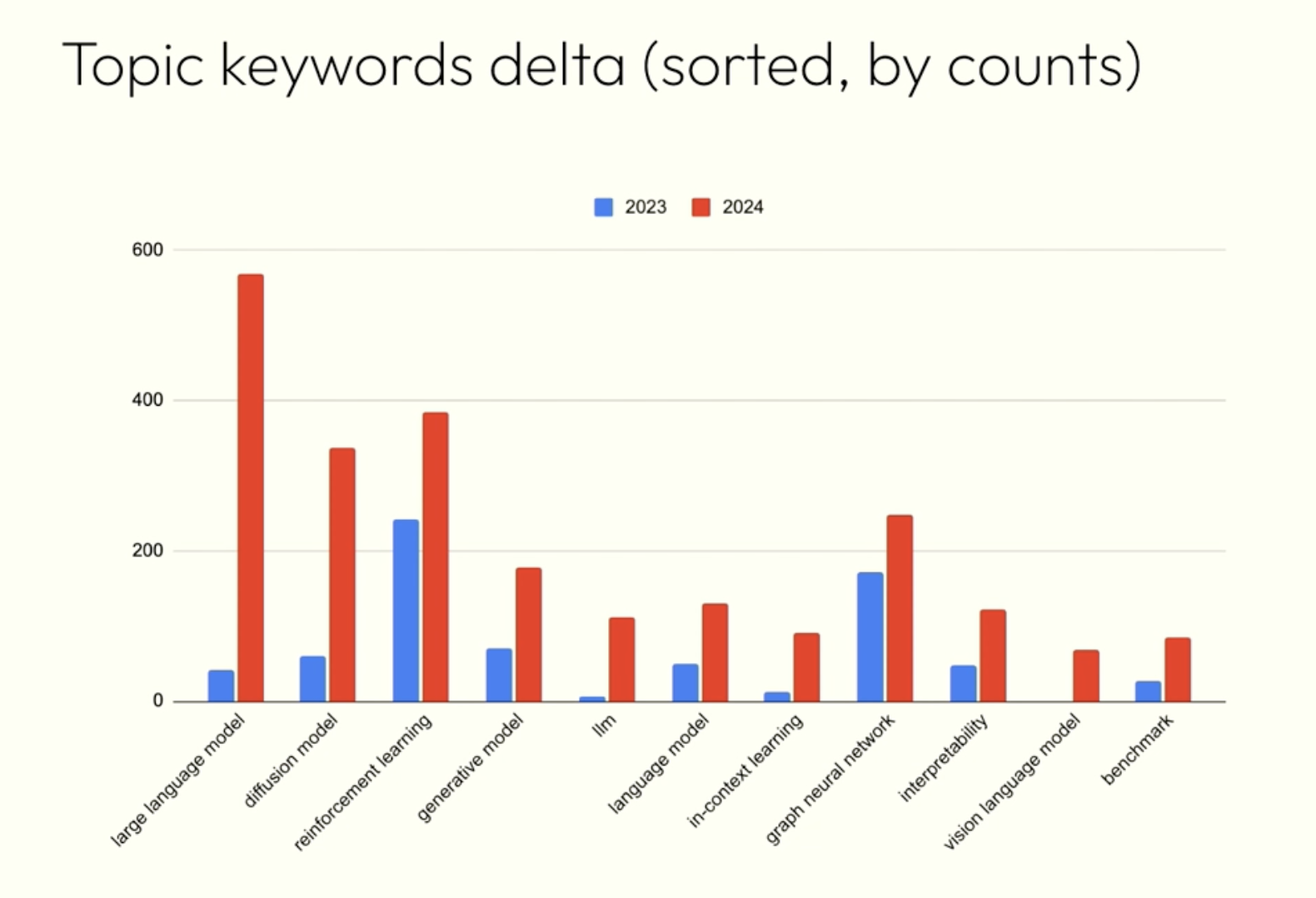
Here’s a screenshot from the opening ceremony, where they discussed the main topics of the conference. While Reinforcement Learning is still going strong, it is no surprise that LLMs and Diffusion Models have made a dramatic increase in relevance compared to 2023, making LLMs the hottest topic in ICLR this year:
Unexpectedly, the conference was largely dominated by men (79.4% of attendees used he/him pronouns), which was a bit disappointing. There is so much to do in the diversity and inclusion fronts overall in the world of Machine Learning and AI, even though I appreciate the efforts of the organization to correct these biases in most invited talks and session chairs.
Now that I’m back home, I wanted to share some of the highlights from the conference, including the top 10 papers that I found most interesting. The following list is biased towards audio and music, and it is of course my personal opinion. The proceedings are so vast that I am sure I am missing some gems. But in any case, I hope that you find it useful!
Top 10 ICLR 2024 Papers
(In no particular order)
Multi-Source Diffusion Models for Simultaneous Music Generation and Separation
Nice formulation of diffusion models targeted to source separation and music generation, all at once. I love this end-to-end approach that yields several tasks in a single model: (i) full music generation; (ii) generation of a given instrument given a mixture; and (iii) plain good old source separation. Demo and code here.
Revisiting Deep Audio-Text Retrieval Through the Lens of Transportation
This work presents a novel approach to audio-text retrieval by leveraging the concept of transportation and learning to match. Obtains state-of-the-art results on several benchmarks, including AudioCaps, Clotho, and ESC-50. Seems to be performing pretty well for Sound Event Detection too! Code available here.
Zipformer: A faster and better encoder for automatic speech recognition
This is a more efficient and effective version of the Conformer model. They additionally include a couple of novel “Swoosh” activation functions that seem to yield better results. Yields SOTA for ASR, and seems to be working well for Audio Tagging as well. Code available here.
Large Language Models are Efficient Learners of Noise-Robust Speech Recognition
Very interesting way of using large language models for speech recognition. Basically, LLMs take care of Generative Error Correction, which makes ASR models way more robust. Code available here.
An Investigation of Representation and Allocation Harms in Contrastive Learning
A nice framework to better understand the biases in data when training contrastive models. The paper shows how such biases can result in representation harm, which collapses one underrepresented class into another. This can result in allocation harm in downstream tasks, where the model is not able to correctly classify the underrepresented class. Code available here.
Vocos: Closing the gap between time-domain and Fourier-based neural vocoders for high-quality audio synthesis
And the phase recovery saga continues! This work proposes an efficient method to recover the phase in Fourier-based neural vocoders, resulting in an approach that is an order of magnitude faster than previous methods like HiFi-GAN. Code available here, make sure you checkout the demo, it has such impressive results!
Improved baselines for vision-language pre-training
New framework called CLIP Rocket (CLIP🚀 for short)! CLIP🚀 includes several tricks in the original CLIP recipe that improve the performance of the model. Code available here.
Masked Audio Generation using a Single Non-Autoregressive Transformer
Fantastic non-autoregressive model for audio generation. They use RVQ to compress the audio signal, not too different than VampNET. Results are quite impressive! Code and demo here.
RTFS-Net: Recurrent Time-Frequency Modelling for Efficient Audio-Visual Speech Separation
Interesting multi-modal work for video-audio understanding and speech separation. The authors leverage a LipReading model with ResNet18 on several video frames combined with the audio to better achieve speech separation. Code here.
Sentence-level Prompts Benefit Composed Image Retrieval
Another work that leverages LLMs to better guide models! In this case, focused on improving Composed Image Retrieval (CIR), the task of using a specific image to retrieve a similar one with an additional text condition. Code available here.
Bonus Content
While the poster presentations were generally good, a couple of them stood out with their smart and engaging presentations, including some cool “swag” in form of cards!
Here a couple of pictures of them:


Thanks authors for making such presentations great, it was so nice to chat with you, even if these research topics were a bit far from my main interests.
Finally, congrats to my co-authors for their fantastic work on the paper CompA: Addressing the Gap in Compositional Reasoning in Audio-Language Models, which was presented at the conference. Here you have a little picture I took after the session was over:

And last thing: I had the most interesting hotel room ever: right next to a roller coaster! The conference was held just 5 minutes walking from an amusement park called Prater (apparently an institution in Vienna), and my room was right next to the roller coaster (i.e., not quiet).

(of course I ended up riding the roller coaster, and it was more intense –and fun– than I expected!)